Making curl impersonate Firefox
Update: The second part about impersonating Chrome is up.
In the last post I analyzed an API used by a website to fetch data and display it to the user. I did that in order to automate fetching that same data once a day. The API required customized HTTP headers which I guess were some sort of bot protection. This time I faced a much more sophisticated mechanism: a commercial bot protection solution.
Bot protections are designed to protect websites against web scraping. There are a lot of commercial solutions available by known companies. Here I was getting blocked by one of them, let’s call the company by the fake name Protectify.
My motivation was similar to the last post. I wanted to perform a single GET request to a webpage automatically once a day. When using the browser, the website immediately returns the correct content. However, when using curl or a Python script to perform the exact same GET request, we get back:
HTTP/1.1 503 Service Temporarily Unavailable
...
Server: protectify
...
Checking your browser before accessing www.secured-by-protectify.com
This process is automatic. Your browser will redirect to your requested content shortly.The returned HTML also contains some obfuscated Javascript code. Basically what’s happening is that the website is served by Protectify’s servers. They somehow detected the use of an automated tool to perform the HTTP request, and served us a Javascript-based challenge that only a real browser would be able to solve.
The data I was trying to fetch was publicly available information which could be taken from other sources. However, this piqued my interest. A real browser does not get the JS challenge, but is immediately served the real content. How could Protectify know that I was using curl to access the website?
TL;DR
- Protectify’s servers fingerprint the HTTP client used (e.g. browser, curl) before serving back content.
- They use a variety of parameters, most notably the TLS handshake and the HTTP headers.
- In case your fingerprint does not match that of a known browser, the Javascript challenge is served instead of the real content.
To bypass it,
- I compiled a special version of
curlthat behaves, network-wise, identically to Firefox. I called itcurl-impersonate. curl-impersonateis able to trick Protectify and gets served the real content.- You can find a Docker image that compiles it in this repository.
This was done in a very hacky way, but I hope the findings below could be turned into real project. Imagine that you could run:
curl --impersonate ff95
and it would behave exactly like Firefox 95. It can then be wrappped with a nice Python library.
Anyway, here are the technical details.
The technical details
Let’s try to understand how Protectify identifies that we are a bot. At first I tried to send the exact same HTTP headers that Firefox sends. I used Firefox 95 on a Windows virtual machine to see what headers are sent. I then ran curl with the exact same headers:
$ curl 'https://secured-by-protectify.com'
-H 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:95.0) Gecko/20100101 Firefox/95.0' \
-H 'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8' \
-H 'Accept-Language: en-US,en;q=0.5' \
-H 'Accept-Encoding: gzip, deflate, br' \
-H 'Connection: keep-alive' \
-H 'Upgrade-Insecure-Requests: 1' \
-H 'Sec-Fetch-Dest: document' \
-H 'Sec-Fetch-Mode: navigate' \
-H 'Sec-Fetch-Site: none' \
-H 'Sec-Fetch-User: ?1'This doesn’t work. We get back HTTP/1.1 503 Service Temporarily Unavailable.
There is also an open-source Python package which claims to “bypass Protectify’s anti-bot page”. It didn’t work with this site as well.
The TLS handshake
When an HTTP client opens a connection to a website with SSL/TLS enabled (i.e. https://…) it first performs a TLS handshake. The handshake’s purpose is to verify the other side’s authenticity and establish the encrypted connection. The first message sent by the client is called “Client Hello” and it contains quite a lot of TLS parameters. Here is a Wireshark capture from a regular curl invocation:
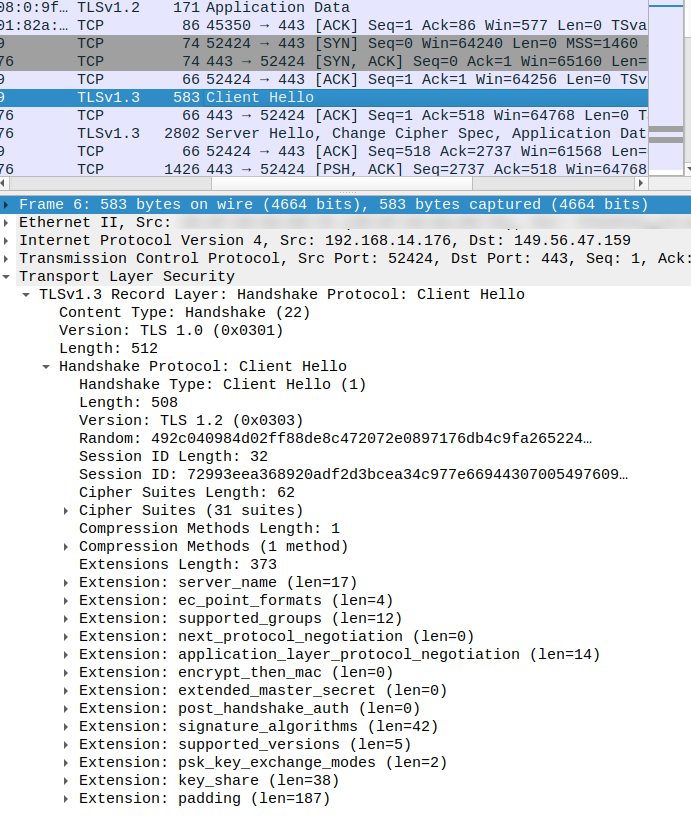
I’m far from a TLS expert, but it is clear that in this message alone there is a myriad of parameters, extensions and configurations which are sent by our client. Each TLS client will send a different “Client Hello” message, and it has been known for a long time that it can be used to identify which browser or tool initiated the connection. See, for example, the ja3 project.
The “Cipher Suites” list
Part of the “Client Hello” message is the Cipher Suites list, visible above. It indicates to the server what encryption methods the client supports. This is how curl’s cipher suite looks like by default:
Cipher Suites (31 suites)
Cipher Suite: TLS_AES_256_GCM_SHA384 (0x1302)
Cipher Suite: TLS_CHACHA20_POLY1305_SHA256 (0x1303)
Cipher Suite: TLS_AES_128_GCM_SHA256 (0x1301)
Cipher Suite: TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384 (0xc02c)
Cipher Suite: TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384 (0xc030)
Cipher Suite: TLS_DHE_RSA_WITH_AES_256_GCM_SHA384 (0x009f)
Cipher Suite: TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305_SHA256 (0xcca9)
...
Notably, curl sends 31 different possible ciphers. Compare it to Firefox’s 17, which are also ordered differently:
Cipher Suites (17 suites)
Cipher Suite: TLS_AES_128_GCM_SHA256 (0x1301)
Cipher Suite: TLS_CHACHA20_POLY1305_SHA256 (0x1303)
Cipher Suite: TLS_AES_256_GCM_SHA384 (0x1302)
Cipher Suite: TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256 (0xc02b)
Cipher Suite: TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256 (0xc02f)
Cipher Suite: TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305_SHA256 (0xcca9)
Cipher Suite: TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305_SHA256 (0xcca8)
...
It is highly likely that Protectify uses this list to detect known browsers. Hence my first attempt was to cause curl to use the same cipher suite as Firefox. I converted the list to OpenSSL’s format using this reference and tried my luck with the --ciphers option:
$ curl 'https://secured-by-protectify.com'
--ciphers TLS_AES_128_GCM_SHA256,TLS_CHACHA20_POLY1305_SHA256,TLS_AES_256_GCM_SHA384,ECDHE-ECDSA-AES128-GCM-SHA256,ECDHE-RSA-AES128-GCM-SHA256,ECDHE-ECDSA-CHACHA20-POLY1305,ECDHE-RSA-CHACHA20-POLY1305,ECDHE-ECDSA-AES256-GCM-SHA384,ECDHE-RSA-AES256-GCM-SHA384,ECDHE-ECDSA-AES256-SHA,ECDHE-ECDSA-AES128-SHA,ECDHE-RSA-AES128-SHA,ECDHE-RSA-AES256-SHA,AES128-GCM-SHA256,AES256-GCM-SHA384,AES128-SHA,AES256-SHA
-H 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:95.0) Gecko/20100101 Firefox/95.0' \
...well, it fails. 503 Service Temporarily Unavailable again. Looking at Wireshark, the cipher suite contains 18 ciphers, even though we requested only 17. OpenSSL, the library curl uses by default for TLS, had automatically added the following cipher:
Cipher Suite: TLS_EMPTY_RENEGOTIATION_INFO_SCSV (0x00ff)
This behavior is documented by OpenSSL but I could not find a way to disable it. This makes it extremely easy to detect OpenSSL clients. curl and Python use OpenSSL, but no major browser does. We’ll have to choose a different route.
Using NSS
Firefox does not use OpenSSL. It uses NSS, another library for TLS communications. Luckily, curl can be compiled against a large range of TLS libraries, NSS included. So I compiled curl against NSS instead of OpenSSL. This was pretty techinical and took a while to figure out. You can find the full build procedure at the repository. The resulting binary I named curl-impersonate.
With this in hand, I converted once more the cipher list into the right format, which can be found in this curl source file. Running our new curl-impersonate:
$ curl-impersonate 'https://secured-by-protectify.com'
--ciphers aes_128_gcm_sha_256,chacha20_poly1305_sha_256,aes_256_gcm_sha_384,ecdhe_ecdsa_aes_128_gcm_sha_256,ecdhe_rsa_aes_128_gcm_sha_256,ecdhe_ecdsa_chacha20_poly1305_sha_256,ecdhe_rsa_chacha20_poly1305_sha_256,ecdhe_ecdsa_aes_256_gcm_sha_384,ecdhe_rsa_aes_256_gcm_sha_384,ecdhe_ecdsa_aes_256_sha,ecdhe_ecdsa_aes_128_sha,ecdhe_rsa_aes_128_sha,ecdhe_rsa_aes_256_sha,rsa_aes_128_gcm_sha_256,rsa_aes_256_gcm_sha_384,rsa_aes_128_sha,rsa_aes_256_sha
-H 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:95.0) Gecko/20100101 Firefox/95.0' \
-H ...and… it fails again. However, looking at Wireshark, the Cipher Suite option now matches exactly the one Firefox sends. Left is curl-impersonate, right is Firefox:
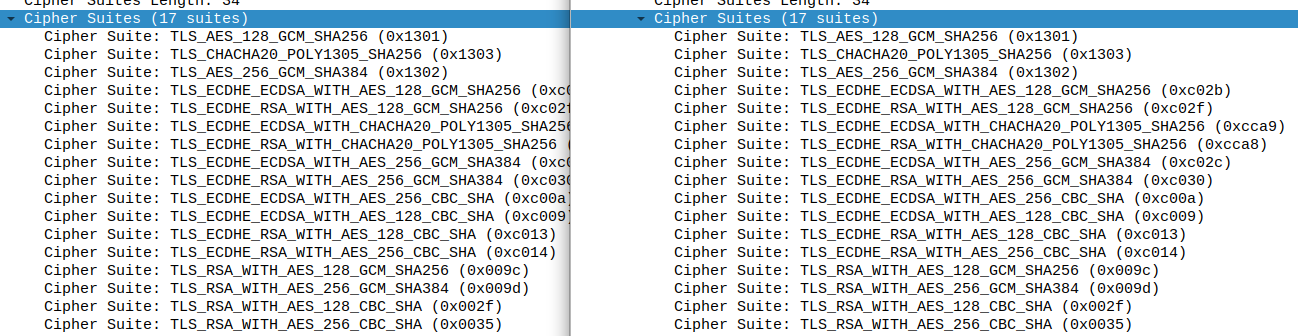
So we are in the right direction.
The rest of the Client Hello message
The Cipher Suites is just one part of the Client Hello message. Most importantly, the Client Hello contains a list of TLS extensions. Each client produces a different set of extensions by default. Anti-bot mechanisms use this to identify which HTTP client was used. The goal here was to make curl-impersonate produce the exact same extension list as Firefox. I will detail some of the process. The bottom line is that by playing with curl’s source code, and putting in the right modifications, I managed to make its Client Hello message look exactly like Firefox’s.
Here is the Client Hello message that Firefox sends by default (Firefox 95, Windows, non-incognito):
Handshake Protocol: Client Hello
Handshake Type: Client Hello (1)
Length: 508
Version: TLS 1.2 (0x0303)
...
Session ID Length: 32
Session ID: 22de422dd343bb2bccead1e060098037ae5793bae952b20c…
...
Extensions Length: 401
Extension: server_name (len=17)
Extension: extended_master_secret (len=0)
Extension: renegotiation_info (len=1)
Extension: supported_groups (len=14)
Extension: ec_point_formats (len=2)
Extension: session_ticket (len=0)
Extension: application_layer_protocol_negotiation (len=14)
Extension: status_request (len=5)
Extension: delegated_credentials (len=10)
Extension: key_share (len=107)
Extension: supported_versions (len=5)
Extension: signature_algorithms (len=24)
Extension: psk_key_exchange_modes (len=2)
Extension: record_size_limit (len=2)
Extension: padding (len=138)
Here are some of the notable changes I made to curl so that it sends the exact same message.
ALPN and HTTP2
The presence of the application_layer_protocol_negotiation extension can be seen above. This is known as ALPN. This extension is used by browsers to negotiate whether to use HTTP/1.1 or HTTP/2. By doing it as part of the TLS handshake, the browser saves a few round-trips which would otherwise happen only after the TLS session has been established. The extension’s contents look like the following:
Extension: application_layer_protocol_negotiation (len=14)
Type: application_layer_protocol_negotiation (16)
Length: 14
ALPN Extension Length: 12
ALPN Protocol
ALPN string length: 2
ALPN Next Protocol: h2
ALPN string length: 8
ALPN Next Protocol: http/1.1
Here Firefox tells the server that it supports both HTTP/2 (h2) and HTTP/1.1 (http/1.1).
To reproduce this behavior, I:
- Compiled curl with nghttp2, the low-level library that provides the HTTP/2 implementation.
- Made a small modification to Curl’s code, since it was sending
h2andhttp/1.1in reverse order. - Launched curl with the
--http2flag.
A few other extensions
Firefox adds the status_request and delegated_credentials extensions as can be seen above. I don’t know what they do, but curl wasn’t sending them. Here the solution was to look at the Firefox source code. Mozilla provides searchfox, a whole site dedicated to searching the Firefox source code. It’s great! The two important files are nsNSSIOLayer.cpp and nsNSSComponent.cpp. Searching around I found the following two snippets:
// CommonInit() @ nsNSSComponent.cpp
SSL_OptionSetDefault(
SSL_ENABLE_DELEGATED_CREDENTIALS,
Preferences::GetBool("security.tls.enable_delegated_credentials",
DELEGATED_CREDENTIALS_ENABLED_DEFAULT));// nsSSLIOLayerSetOptions() @ nsNSSIOLayer.cpp
if (SECSuccess != SSL_OptionSet(fd, SSL_ENABLE_OCSP_STAPLING, enabled)) {
return NS_ERROR_FAILURE;
}So Firefox turns on some specific SSL options called SSL_ENABLE_DELEGATED_CREDENTIALS and SSL_ENABLE_OCSP_STAPLING . Without really understanding what’s their purpose, I added similar snippets to curl, and now it sends the desired extensions in the Client Hello. I continued this process for 7 or 8 extensions in total. Some were missing, some were configured differently, and it took some tinkering to figure everything out. The full patch can be found at the repo.
Session ID
TLS Session IDs are another optimization mechanism that saves the browser from re-doing a full TLS handshake. Quoting from this book:
… the client can include the session ID in the ClientHello message to indicate to the server that it still remembers the negotiated cipher suite and keys from previous handshake and is able to reuse them. In turn, if the server is able to find the session parameters associated with the advertised ID in its cache, then an abbreviated handshake (Figure 4-3) can take place.
But here is the curious thing: Firefox always includes a session ID, even when connecting to a never-visited-before site. This is how it looks:
Session ID Length: 32
Session ID: 22de422dd343bb2bccead1e060098037ae5793bae952b20c…
while curl’s is just empty:
Session ID Length: 0
This took quite a deep look in the NSS/Firefox source code to figure out. The relevant function is ssl3_CreateClientHelloPreamble which builds the Client Hello message. Under certain circumstances, it adds a fake session ID:
...
else if (ss->opt.enableTls13CompatMode && !IS_DTLS(ss)) {
/* We're faking session resumption, so rather than create new
* randomness, just mix up the client random a little. */
PRUint8 buf[SSL3_SESSIONID_BYTES];
ssl_MakeFakeSid(ss, buf);
rv = sslBuffer_AppendVariable(&constructed, buf, SSL3_SESSIONID_BYTES, 1);
}I don’t really understand why. If anyone does, please let me know1. To enable similar behavior in curl-impersonate I had to turn on “TLS1.3 compat mode” (which can be seen in the if condition above). Firefox does this as well. This is from the Firefox code:
// nsSSLIOLayerSetOptions() @ nsNSSIOLayer.cpp
// Set TLS 1.3 compat mode.
if (SECSuccess != SSL_OptionSet(fd, SSL_ENABLE_TLS13_COMPAT_MODE, PR_TRUE)) {
...Putting a similar call in curl-impersonate makes it send fake sesssion IDs a well.
The result
The resulting curl binary, after all source-code modifications and using the right flags, sends a TLS Client Hello message that looks exactly like the one Firefox sends. Here is a side-by-side comparison:
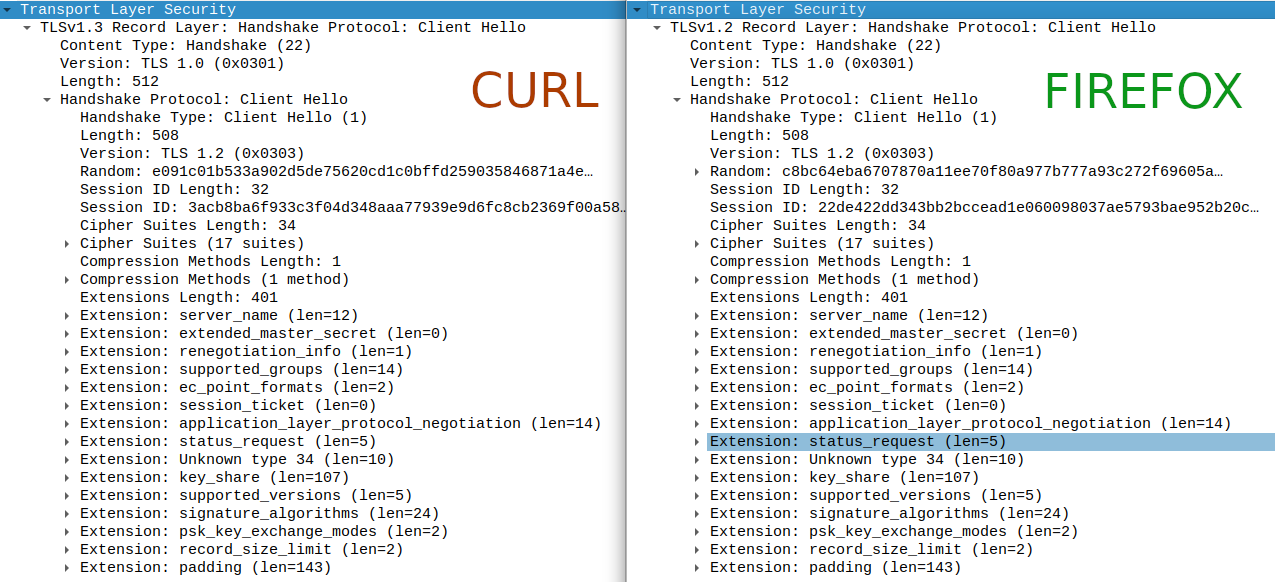
I can’t tell the difference, and Protectify can’t either. It bypasses the bot protection entirely.
This repository contains a Dockerfile that will build it for you. The resulting image includes:
curl-impersonate, a modified curl binary with all the required TLS tweaks.curl_ff95, a wrapper bash script that will launchcurl-impersonatewith the correct parameters to make it look like Firefox 95 on Windows.
Concluding
The modified curl behaves like a real browser, at least from the TLS viewpoint. It bypasses this specific company’s bot protection mechanism.
Honestly, that company did a pretty great job there. If your TLS handshake and HTTP headers don’t exactly match that of a real browser, you get blocked. If you use a real browser, you don’t notice anything. I would use their solution if I needed one.
Remember that this was just one bot protection mechanism. There are others which are more aggressive. I don’t expect the above to work for you if you do massive web scraping. For fetching a single page once a day it works well, at least until they figure it out and update their bot protection to use other tricks.
-
Update: I now understand that this was implemented as a bridge for adoption of TLS 1.3. More information in this Cloudflare blog post. ↩