Analyzing a stock exchange's API
This was a fun afternoon reverse engineering project so I figured I’d write a bit about it.
I’m developing a web app, Pumbaa Backtester, which is a small tool to simulate the historical performance of index-based investments. As part of the development I wanted to fetch long-term historical data for an ETF traded at a medium-size stock exchange. I won’t write exactly which one, but if you are curious you’ll figure it out.
Each day a closing price for the ETF is determined, which is pretty much like the price of a stock at the end of the trading day. What I needed are closing prices since the ETF was created 22 years ago. Browsing a bit at the stock exchange’s site I got to the following form:
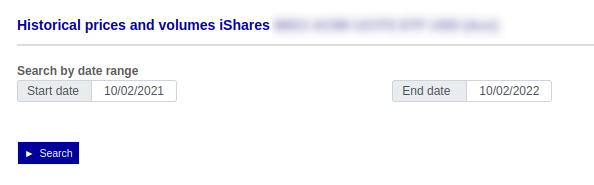
Great! This gives the data I want. The goal is to automate fetching these prices - I want it to be done automatically once a day. So let’s fire up Firefox network monitor (Ctrl+Shift+E) and see what happens when we press “Search”:
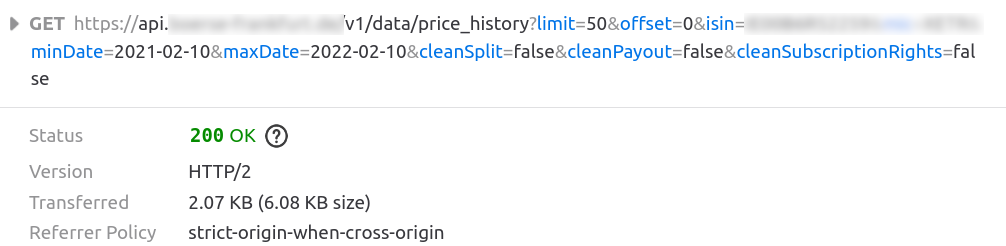
Looks simple enough - an API with the parameters isin (unique id of the ETF), minDate and maxDate.
First attempts
If we attempt to access the API with curl:
$ curl -X GET -G \
'https://api.stock-exchange.com/v1/data/price_history' \
-d "limit=50" \
-d "offset=0" \
-d "isin=$ISIN" \
-d "minDate=2021-02-10" \
-d "maxDate=2022-02-10" \
-d "cleanSplit=false" \
-d "cleanPayout=false" \
-d "cleanSubscriptionRights=false"
{}we get back an empty JSON response. At this point the most likely possibility is that we are missing one of the HTTP headers, it can be a Cookie header or something else. Looking at the original request’s headers, everything is quite standard except for the trio Client-Date, X-Client-TraceId and X-Security:
Client-Date: 2022-02-12T08:58:52.208Z
X-Client-TraceId: bbbfec1ad15ca1e16cd72fba9e8a7241
X-Security: 185111eb1d17ea0bf0928f2655d05254These are not documented on MDN so they must be something unique to this API. You could wonder if we could just send the exact same headers again, and yes it works for a few minutes, but then stops working. We’ll have to find out the logic behind them.
Client-Date is simple enough, it’s just the current time. The other two are 16-byte hex encoded strings, so maybe they are just random UUIDs? Let’s try:
$ curl -X GET -G \
'https://api.stock-exchange.com/v1/data/price_history' \
-H "Client-Date: 2022-02-12T08:58:52.208Z" \
-H "X-Client-TraceId: $(uuidgen -r | tr -d '-')" \
-H "X-Security: $(uuidgen -r | tr -d '-')" \
-d 'limit=50' \
...
{}Nope, another empty JSON. There must be some logic then that generates these headers in Javascript.
Finding the origin
Searching for the string X-Client-TraceId through the JS scripts that the page uses, we find the culprit:
The script main-es2015.3f13e42ead3dc41c6dc3.js is a one-line, minified script, probably generated by webpack. Why would a page with a single form need 3MB of Javascript is really beyond me. Anyway, after beautifying it we can look at the snippet that generates the three headers:
class o {
static generateHeaders(t) {
const e = i().toISOString();
let n = e + t + r.N.tracing.salt;
return n = s.V.hashStr(n).toString(), {
"Client-Date": e,
"X-Client-TraceId": n,
"X-Security": s.V.hashStr(i().format("YYYYMMDDHHmm")).toString()
}
}
}At first I tried to approach this like a programmer, understanding where each variable comes from. But in a 90k-line script where everything is called t, i, and r it’s quite impossible. It doesn’t help that the surrounding code looks like some form of alien code:
63205: function(t, e, n) {
"use strict";
n.d(e, {
N: function() {
return o
}
});
var i = n(16738),
r = n(92340),
s = n(9346);
class o {
static generateHeaders(t) {
...
}
}
}So let’s just use some common sense and go header-by-header:
Client-Date
This is the current time, converted to a string with Javascript’s toISOString() function.
X-Security
Here is the snippet again for convenience:
"X-Security": s.V.hashStr(i().format("YYYYMMDDHHmm")).toString()We can guess that it’s a hash of the current time, after being converted to the format YYYYMMDDHHmm. Which hash? The result is 16-byte long so the most probable candidate is md5. Let’s check:
$ echo -n '202202120858' | md5sum
f627c44850a16146d60590eb9584bac3Doesn’t match… maybe we need to use the local time instead?
$ echo -n '202202121058' | md5sum
185111eb1d17ea0bf0928f2655d05254It matches! So we got this header as well.
X-Client-TraceId
Here’s the relevant part again:
const e = i().toISOString();
let n = e + t + r.N.tracing.salt;
return n = s.V.hashStr(n).toString(), {
"X-Client-TraceId": n,
...
}Leveraging what we found out already, this header is generated as follows:
- The current time,
e, is concatenated to two unknown strings,tandsalt. X-Client-TraceIdis the md5 hash of the result.
Now the fastest thing to do is to use a Javascript debugger to find out what t and salt are.
The Firefox debugger (Ctrl+Shift+Z) lets us beautify the script and put a breakpoint on this line. Hitting “Search” again the breakpoint is triggered, and we can see the variables’ values:
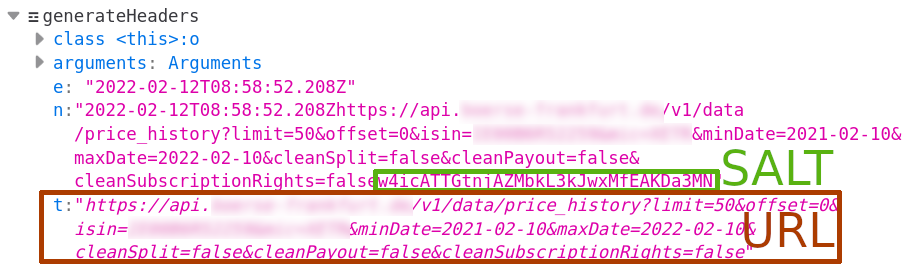
So apparently:
tis the requested URL, including the query string.saltis a fixed string, in this casew4icATTGtnjAZMbkL3kJwxMfEAKDa3MN. Apparently it appears in the source code as-is so it must be constant.X-Client-TraceIdis the md5 oftime + url + salt.
Now we have all the information needed to generate valid requests to the API:
- Take the current time and hash it to generate
X-Security. - Construct the URL with the parameters, add it to the time and salt and hash everything together to generate
X-Client-TraceId.
And it works! Here is a Python snippet to generate the headers for a given URL:
import datetime
import hashlib
def generate_headers(url):
salt = "w4icATTGtnjAZMbkL3kJwxMfEAKDa3MN"
current_time = datetime.datetime.now(tz=datetime.timezone.utc)
client_date = (current_time
.isoformat(timespec="milliseconds")
.replace("+00:00", "Z")
)
client_traceid = hashlib.md5(
(client_date + url + salt).encode("utf-8")
)
security = hashlib.md5(
current_time.strftime("%Y%m%d%H%M").encode("utf-8")
)
return {
"Client-Date": client_date,
"X-Client-TraceId": client_traceid.hexdigest(),
"X-Security": security.hexdigest()
}Concluding
What was the purpose of these headers? I’m really not sure. It could be protection against bots or maybe a user-tracking mechanism. Anyway, it didn’t take much work to understand it. I guess if you are exposing your API on the internet, expect someone to figure it out and use it.